Measurement and uncertainty
Bayesian Methods for Ecological and Environmental Modelling
Terminology for measurements
- “The Facts”
- Evidence
- Observations
- Measurements
- Data
All the same thing, increasing uncertainty. ![]()
Measuring stream flow

The stream flow rate \(Q\) is the product of the stream cross-sectional area and its velocity. A pressure transducer continuously records stream height \(h\) via the pressure, \(P_{\mathrm{stream}}\).
Uncertainty in upscaling
Often, true process of interest is a larger-scale property (e.g. annual sum, regional mean)
- integration
- interpolation / extrapolation,
- accounting for small-scale heterogeneity
- adds additional modelling steps
The Reproducibility Crisis

1. Low prior probabilities

Example: Land-use change

2. Low statistical power

2. Effect of low power

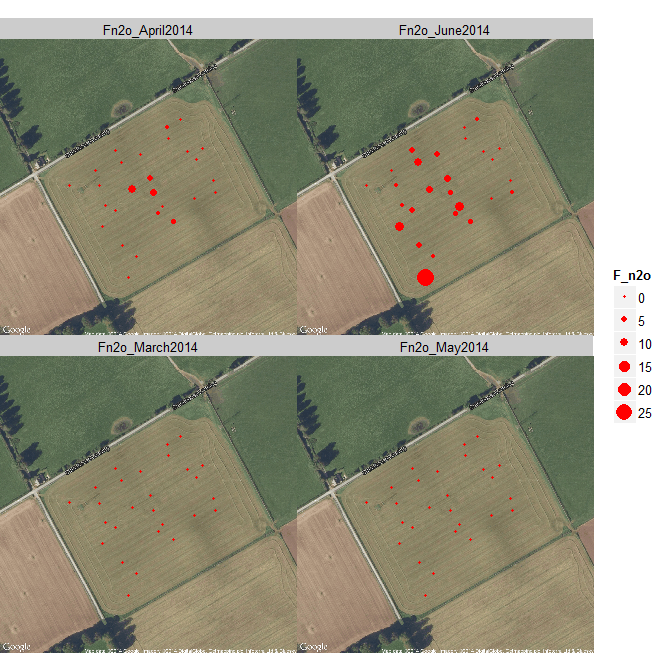
Example: gas emissions from soil

Spatial variation in gas emissions

We need cumulative emissions

3. Bias in observation process

Example: soil carbon change
3. Effect of bias

Measuring soil carbon: field

 Take soil cores
Take soil cores 
Measuring soil carbon: lab

Soil carbon: integrate over depth
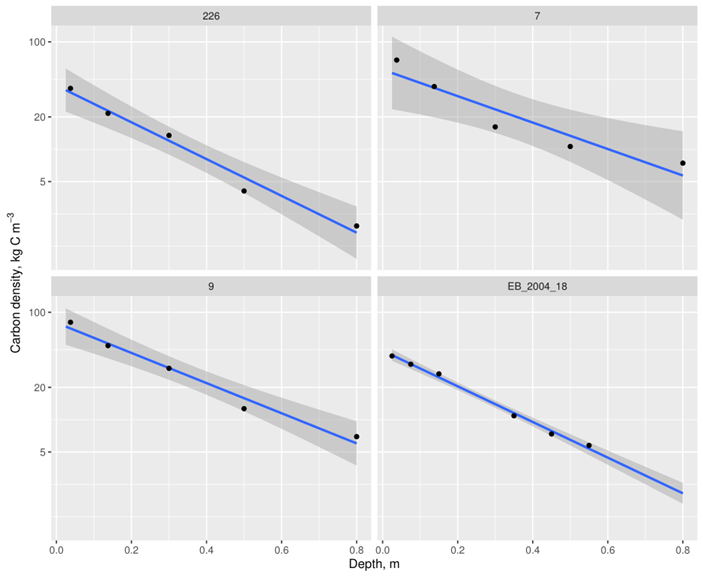
\(\mathrm{log} C = \alpha + \beta \times \mathrm{depth}\)
Soil carbon: integrate over space
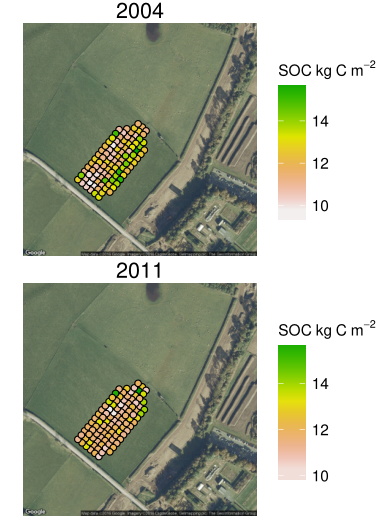
Extrapolate samples to whole field with spatial model
\(\mu_{\mathrm{field}} = f(\theta, C_{\mathrm{samples}})\)
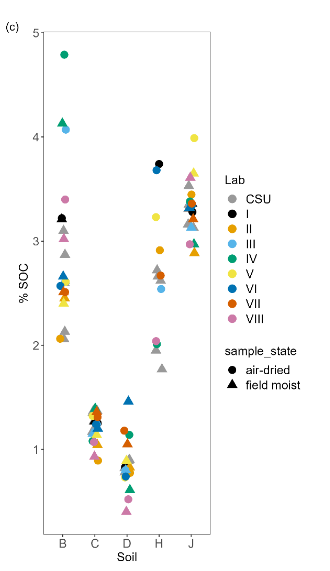
Soil carbon: same soil, different labs
Soil carbon: real data

Soil carbon: real data

“Why most published research findings are false”
- The multiple testing problem

“Why most published research findings are false”
- The multiple testing problem

Unpublished work as Dark Matter

We can only see 5% of the universe.
Solutions

Don’t focus on testing a null hypothesis.
Solutions

Pre-register and publish all results.
The ASA statement

2016
 2019
2019
Stop using p values and “statistical significance”.
Summary
“All models are wrong, but some are useful.”
George Box, 1976.

Summary
“All models are wrong, but some are useful.”
George Box, 1976.
“All data are wrong, but some are useful.”
